Following my previous post on classifying 10K Latin(?) books, I started an automatic process to re-OCR the ~300 works in the set which didn’t have plaintext OCR results already available. About mid-way through the run of this process, I realized that most of these do in fact have some form of OCR available, but only as DjVu XML output from ABBYY FineReader. That means that not only could we potentially use that OCR text for our text classification process, but also that we can compare how that process works with ABBYY’s OCR text versus our OCR results.
This leads me in to the actual problem I want to deal with in this post, which is trying to come up with a method for automatically evaluating OCR quality with no ground truth. Anyone who’s worked with OCR of historical texts knows bad OCR when they see it, but can we come up with a more general approach we can automatically apply to an entire corpus, to automatically find and prioritize candidates for reprocessing? 1
Related Work
A lot of work has been published on OCR post-correction processes, or quantifying OCR accuracy with ground truth, but I wanted to focus solely on standalone ground-truth-free quality metrics for OCR, for which there appears to be relatively less work published: 2 3
-
Ashok C. Popat, A Panlingual Anomalous Text Detector. Proceedings of the 9th ACM symposium on Document engineering. 2009.
Uses an adaptive mixture of character-level N-gram models, which must be trained per-language.
-
Richard Wudtke et al., Recognizing Garbage in OCR Output on Historical Documents. Proceedings of the 2011 Joint Workshop on Multilingual OCR and Analytics for Noisy Unstructured Text Data. 2011.
SVM-based approach which requires a manually classified garbage/non-garbage token training set.
-
Ulrich Reffle et al., Unsupervised profiling of OCRed historical documents. Pattern Recognition Vol. 46, Issue 5, pp.1346–1357. 2013.
A somewhat complicated approach which makes re-implementation difficult. It also requires large corpora and lexica for the languages of interest.4
-
Naveen Sankaran et al., Error Detection in Highly Inflectional Languages. ICDAR. 2013.
Explores combining a dictionary approach with N-grams or SVMs.
-
Beatrice Alex et al., Estimating and rating the quality of optically character recognised text. Proceedings of the First International Conference on Digital Access to Textual Cultural Heritage. 2014.
The described approach is a simple-but-effective dictionary based one.
-
Calculates “SEASR correctability” and quality scores using a rule-based approach.5
-
The Lace Greek OCR project incorporates a ground-truth-free metric called b-score.
This is based on Federico Boschetti’s “textevaluator” package, which uses dictionaries and language-specific rules to determine the likeley “Greekness” of a text.
I wanted something that would give me accuracy for a wide variety of languages, with no pre-filtering or a priori knowledge of the language(s) used in a document. I also didn’t want to depend on spatial information or idiosyncratic confidence values from the OCR engine, for maximum portability (i.e. I want it to work on just plain text). My initial thought was to extend the simple dictionary approach with a large multi-lingual dictionary set, though that could be burdensome to do comprehensively. So, I wondered: can we use the existing langid classifier to get a good approximation of OCR quality?
Our Method
The method proposed here is to use the line-by-line language confidence scores from langid to assign an OCR quality score. Fortunately for us, langid’s normalized confidence scores in line-by-line mode are much more useful for this application than the document-level normalized score. My initial experiments with this approach revealed that there are a number of different ways one could go about using these scores in an OCR quality metric.
My first idea was to classify whitespace-separated blocks of text as garbage/non-garbage using the mean block score and an experimentally-determined threshold, then dividing “garbage” lines from the total number of (non-whitespace) lines to get a “garbageness” score that would be a proxy for OCR quality. The other, simpler approach I came up with was to use the mean normalized confidence score of all non-blank lines; actually what we want is the complement of this value, to get a “mean language uncertainty” score so that a higher value indicates a higher language uncertainty and we can compare it more directly with our “garbageness” score.
Because I want to use this metric to rank OCR results in order to prioritize re-processing, I can compare scores between ABBYY OCR and my OCR under the assumption that my OCR on this data is likely to be better due to the generally abysmal performance of ABBYY on Ancient Greek and Latin. What we want is a good positive correlation between the original score and the score’s improvement in my OCR.
Here are the results of plotting the improvement in OCR quality scores for both “garbageness” and “mean language uncertainty”:
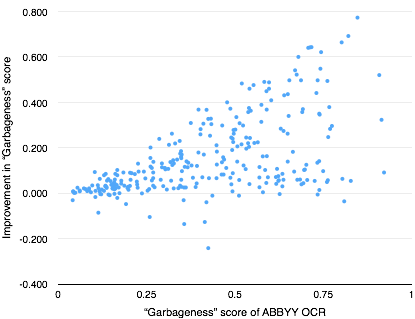
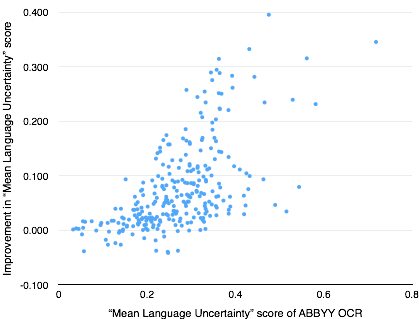
After looking at these graphs, I decided the simple straightforwardness of implementation for “mean language uncertainty” made it a better choice (as there’s no subjective determination of the mean threshold to use for “garbage”).6
Here’s the final version of the Ruby script I came up with for this process:
This script is designed to work on data that has already been processed with langid and combined with the original input, as langid --line -n is the computationally expensive part of this process. This is done with the following very small script:
So you could run this end-to-end with e.g.:
./scorelines.sh filename.txt | ./ocrquality.rb
The advantage of this approach is that it uses the pre-trained statistical language models in langid, enabling easy re-use of this metric (and easy training on your own corpus if the pre-trained models are insufficient). That is, the strength of this approach is the same as that of langid itself: its off-the-shelf usability.7
I’m pretty excited about the potential for this. If we have a repeatable, improvable OCR process, and a reliable ground-truth-free way to approximate accuracy, we can close the loop on a workflow for continuously prioritizing, reprocessing, and improving our OCR results.
Footnotes
-
While writing this, I came across Ted Underwood’s post “The obvious thing we’re lacking” (which, funnily enough, suggests using a language model), which also has some other interesting suggestions for how such a quality metric could be used, e.g. in restricting search results. Ben Schmidt makes an excellent point about OCR metadata in the comments, which is something I’ve been thinking about with this process; I don’t just want to keep the OCR text, I want to keep information about the process as well so I can know if re-processing is likely to give any improvement at all. As noted though, we also want to avoid running afoul of Goodhart’s law, an issue which Ben also raises again here. ↩
-
One could also imagine a quality metric which used the edit distance between raw OCR output and an unsupervised post-correction process (such as those in the simple rule-based heuristic approaches of Taghva et al., Automatic Removal of “Garbage Strings” in OCR Text: An Implementation and Kulp et al., On Retrieving Legal Files: Shortening Documents and Weeding Out Garbage). ↩
-
Something which occurs to me now is that none of these approaches (including mine) really directly confront the problem of OCR hallucination, which is an interesting and difficult problem to consider for any such metric. If the OCR engine hallucinates dictionary words or plausible N-grams, would there be any easy way to detect this “poor quality” output? ↩
-
I was hopeful that there might be an implementation of the algorithm in the open-source PoCoTo, however, this appears to use a client-server model for error profiling, where you must register for an account to have a profiling server generate error profiles for you. I couldn’t find the source for this server, and I doubt that using their server would work well for my needs due to there being an error profiling quota. I also don’t know if their implementation would work well where Latin is the “base” text rather than a “special vocabulary”. ↩
-
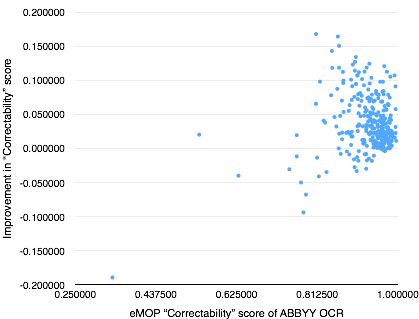
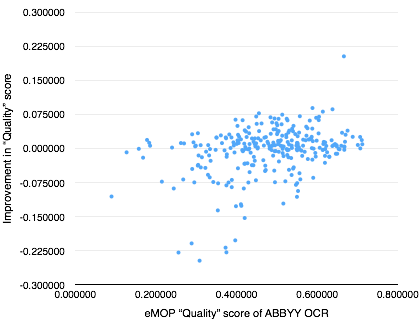
I found this tool quite late into writing this post. For more on how eMOP appears to integrate this scoring into their workflow, see notes about the estimated correctability (ECORR) score on this page. The quality score is computed by cleaning tokens (removing leading and trailing punctuation) and then summing the number of tokens which:
- contain exclusively alpha characters and no 4 or more repeated characters in a run
- are of length at least 3, contain 1-2 non-alpha characters and at least 1 alpha, and no 4 or more repeated characters in a run
Then dividing this by the number of tokens. For “correctability”, this is instead divided by the number of “correctable” tokens, where it ignores from the number of tokens those which are “non-correctable” (single punctuation or character, length < 3, or could represent numbers, dates, amounts of money, identifiers, etc.).
Here are eMOP “correctability” and “quality” scores plotted against their improvement for our data:
-
If you’ve been jumping up and down in your seat, raising your hand, begging to shout “just use entropy you idiots!”, that thought occurred to me as well. You might assume that OCR garbage = random noise = high entropy. The problem with this is that “OCR garbage” can be regular and repeating in the same way that the source documents are; consider an OCR engine which outputs “/0I<au” consistently for every instance of the word “token”. Additionally, it’s entirely possible to have a fundamentally high-entropy source document, where accurate OCR would be high-entropy as well.
As an experiment, here are the results of scoring and comparing entropy on our dataset:
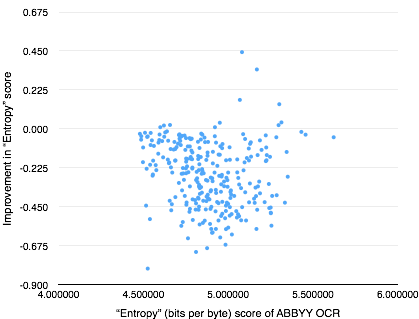
-
It might also be possible to experiment with training
langidon a corpus of “OCR garbage” strings (possibly extracted using an experimentally determined threshold). The issue with this approach is that it may be sensitive to the combination of OCR engine, language, font, etc. used to generate output as training for the “OCR garbage” language. ↩
